
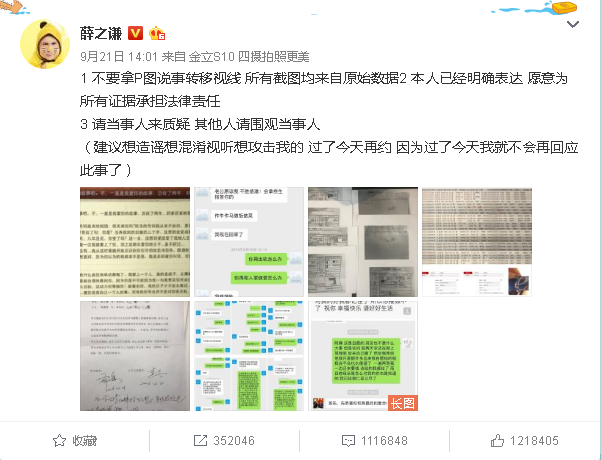
平时我们早上可能会把头条,网易,微博等各种客户端都浏览一遍,来获取各种信息,用爬虫可以做新闻的聚合,把你感兴趣的文章,推送到微信。
上一篇文章我们讲了一个爬虫框架的基本使用方法,现在我们做一个简单的应用,将微博的更新实时推送到微信。
对于信息的获取,现在的软件架构基本有两种方式,一种是pull,还有一种是push。
对于pull,需要我们定期去查询状态,实时性不高,而且大部分时候查询是无效的,但是主动权掌握在信息的消费方。
对于push,当信息更新时,由消息的生产者将消息发送给消费者,实时性高,无谓的消耗小,但是主动权掌握在信息的生产者上。
对于新浪微博,官方并没有提供push的接口,我们只能采用pull的方式。
爬虫每分钟查询一次,发现微博有更新,就把更新的消息发送到微信。
第一步,我们还是要找到需要爬取的内容。手机版新浪微博的界面较为简单,方便我们的爬取。
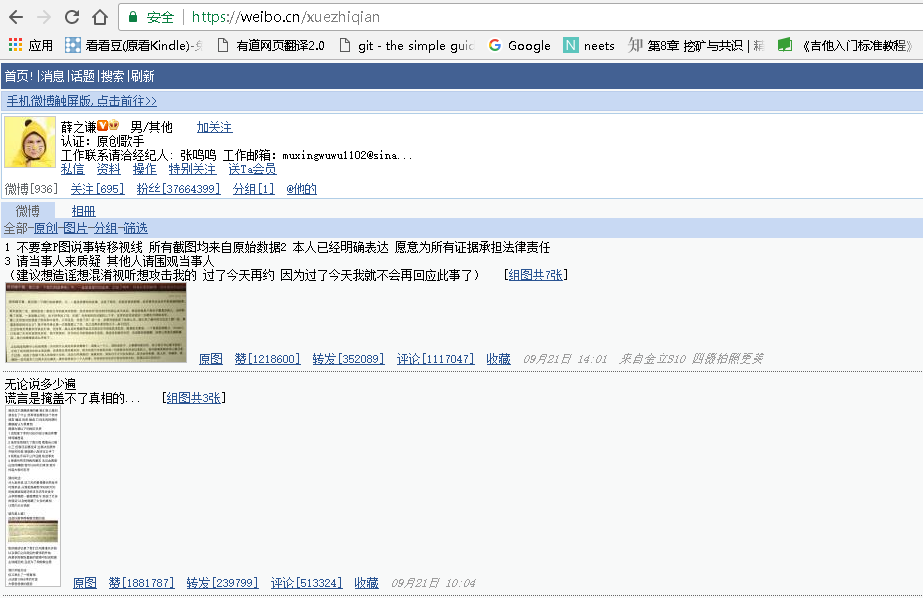
图1
在首页,我们看一下网络请求,找到需要爬取的url
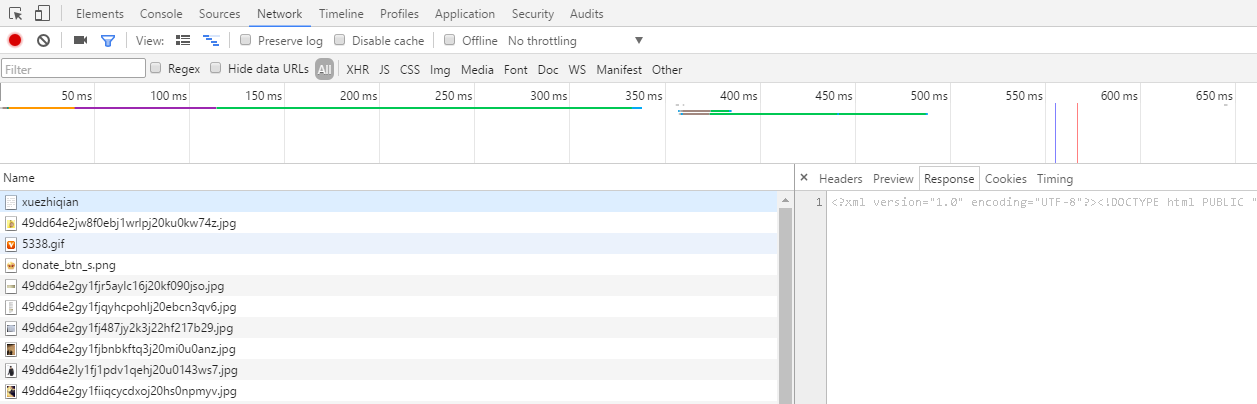
像上一篇文章一样,把我们要爬取的url放进start_urls中
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["xueqiu.com","weibo.cn"]
start_urls = [ #这是要爬取的url
"https://weibo.cn/xuezhiqian"
]
old_id = 'ff'
之后爬取内容,我们要对内容做一些整理,用xpath语法定位到每条微博的内容,同时我们注意到每条微博都有一个id,这个可以用来做微博是否更新的判断依据。每次爬取结束,我们再把同样的url放入队列中
def parse(self, response):
reload(sys)
sys.setdefaultencoding('utf-8')
select_text = response.xpath('//div[@class="c"]/div/span[@class="ctt"]') #定位微博内容
select_id = response.xpath('//div[@class="c"]/@id').extract_first() #定位微博id
content = select_text.extract_first().replace('<br>','\n')[18:-7] #对内容做一些清理
print "old_id "+self.old_id
if select_id != self.old_id:
itchat.send(content, 'filehelper') #发送到微信
self.old_id = select_id
time.sleep(10) #设置爬取的频率
yield scrapy.Request("https://weibo.cn/xuezhiqian", meta={'cookiejar': response.meta['cookiejar']},dont_filter = True) #将请求放入队列,达到循环爬取
发送到微信,使用的是itchat,每次爬虫开始运行前,先扫描二维码登陆微信
def start_requests(self):
itchat.auto_login(hotReload=True)
return [scrapy.Request(url="https://passport.weibo.cn/signin/login?entry=mweibo&r=http%253A%252F%252Fweibo.cn&uid=2657550845&_T_WM=e5426f968c7ee5d45bd438419ba0522d",meta={"cookiejar": 1},callback=self.login_weibo)]
效果如图

这样,一个简单的微博爬虫就完成了,可以发挥自己想象力,比如爬取各个新闻客户端的新闻等等,最好的例子就是今日头条。
下面是全部代码
#encoding:utf-8
import sys
import time
import scrapy
import itchat
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["xueqiu.com","weibo.cn"]
start_urls = [
"https://weibo.cn/xuezhiqian"
]
old_id = 'ff'
def parse(self, response):
reload(sys)
sys.setdefaultencoding('utf-8')
select_text = response.xpath('//div[@class="c"]/div/span[@class="ctt"]')
select_id = response.xpath('//div[@class="c"]/@id').extract_first()
content = select_text.extract_first().replace('<br>','\n')[18:-7]
print "old_id "+self.old_id
if select_id != self.old_id:
itchat.send(content, 'filehelper')
self.old_id = select_id
time.sleep(10)
yield scrapy.Request("https://weibo.cn/xuezhiqian", meta={'cookiejar': response.meta['cookiejar']},dont_filter = True)
def start_requests(self):
itchat.auto_login(hotReload=True)
return [scrapy.Request(url="https://passport.weibo.cn/signin/login?entry=mweibo&r=http%253A%252F%252Fweibo.cn&uid=2657550845&_T_WM=e5426f968c7ee5d45bd438419ba0522d",meta={"cookiejar": 1},callback=self.login_weibo)]
def login_weibo(self, response):
return [scrapy.FormRequest(url="https://passport.weibo.cn/sso/login",formdata={'username':'XXX','password':'XXX'},meta={"cookiejar": 1},callback=self.visit_page)]
def visit_page(self, response):
for i,url in enumerate(self.start_urls):
print url
return [scrapy.Request(url, meta={'cookiejar': response.meta['cookiejar']})]

