
说好要写一篇关于爬虫的,国庆终于有时间了。
首先,爬虫是什么东西,学爬虫能给我们带来什么好处呢?
讲的大白话一点,爬虫就是我们编写的一段程序,定义了如何访问网站,将访问到的数据保存下来。
现在是大数据时代,我们想要的信息,大部分都能在网上找得到。但是这也产生一个数据爆炸的问题,这么多信息,我们人是看不过来的,所以我们需要程序自动化的帮我们做一些事情。将我们的思维逻辑赋予到程序中。
至于好处,首先想到的是这玩意能不能帮我们赚钱啦,和爬虫最相关的,就是股票分析了,像股市的操盘手,每天都要阅读很多行业数据,并分析对市场的影响。我们就用爬虫做这事,我的思路,就是爬到数据后,对市场的情绪进行分析。这是连载,记录我的尝试。爬虫这个东西,说简单也简单,不就是发送请求,然后拿到响应嘛,如果不考虑数据量且大家都这么想,少点套路,多点真诚,那当然是。可是别人不这么想,现在网络上80%的流量都是爬虫,还没等真正的客人来,你就把我服务器撑爆了,这就不答应了。于是,搞各种验证码,访问频率限制,特殊请求头,来限制爬虫,这样爬虫就不是这么好弄了。
好,我们开始,今天先介绍一个框架,scrapy,这个框架封装了很多接口,方便。先来看看它的官网。
安装很简单,我最头疼的就是python安装依赖,经常出现各种错误,这个都没有出现,安装好python,执行
pip install Scrapy
安装好之后,选择一个文件夹,打开命令行,快速生成一个简单的程序模板
scrapy startproject tutorial
这是我生成后的文件目录
然后我们到雪球的官网上看看什么数据我们感兴趣。值得注意的是,你直接看网页的html代码是什么也看不到的,雪球都是通过ajax异步获取数据。查看网络请求,用chrome的调试工具就好。

看,我们找到了雪球头条的内容!激不激动。
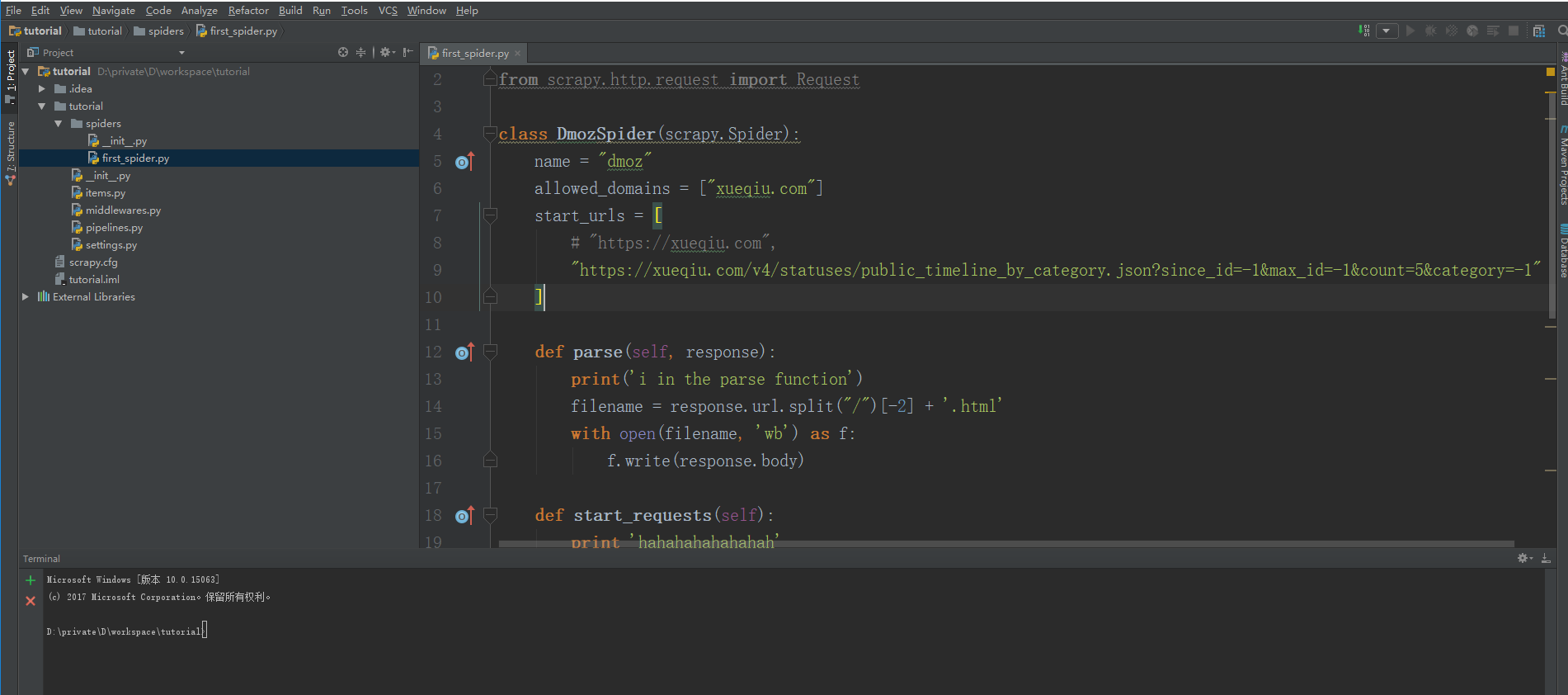
接下来我们继续编写爬虫。在spiders目录下新建一个first_spider.py文件
import scrapy
from scrapy.http.request import Request
class DmozSpider(scrapy.Spider): ###这是我们自己爬虫的类,必须继承scrapy.Soider
name = "dmoz" ###给爬虫起一个名字,没有要求
allowed_domains = ["xueqiu.com"] ###设置允许爬虫爬取的网站
start_urls = [ ###这是我们要爬取的链接的列表
# "https://xueqiu.com",
"https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=-1&count=5&category=-1"
]
def parse(self, response): ###这个函数在发出请求后被调用,这里我们把爬取到的数据保存在文件中
print('i in the parse function')
filename = response.url.split("/")[-2] + '.html'
with open(filename, 'wb') as f:
f.write(response.body)
def start_requests(self): ###这个函数在发出请求前被调用,这里我们先访问首页,拿到cookie,没有cookie,会报400错误
print 'hahahahahahahah'
return [scrapy.Request(url="https://xueqiu.com",meta={"cookiejar": 1},callback=self.visit_page)]
def visit_page(self, response): ###这一步,我们开始真正的请求数据
for i,url in enumerate(self.start_urls):
print url
return [scrapy.Request(url, meta={'cookiejar': response.meta['cookiejar']})]
好,代码我们就编写完了,快不快,爽不爽,所以我们要充分利用现有的工具,快速学习掌握,可以说是程序员的核心能力。接下来我们运行代码。在项目根目录打开命令行,运行
scrapy crawl dmoz
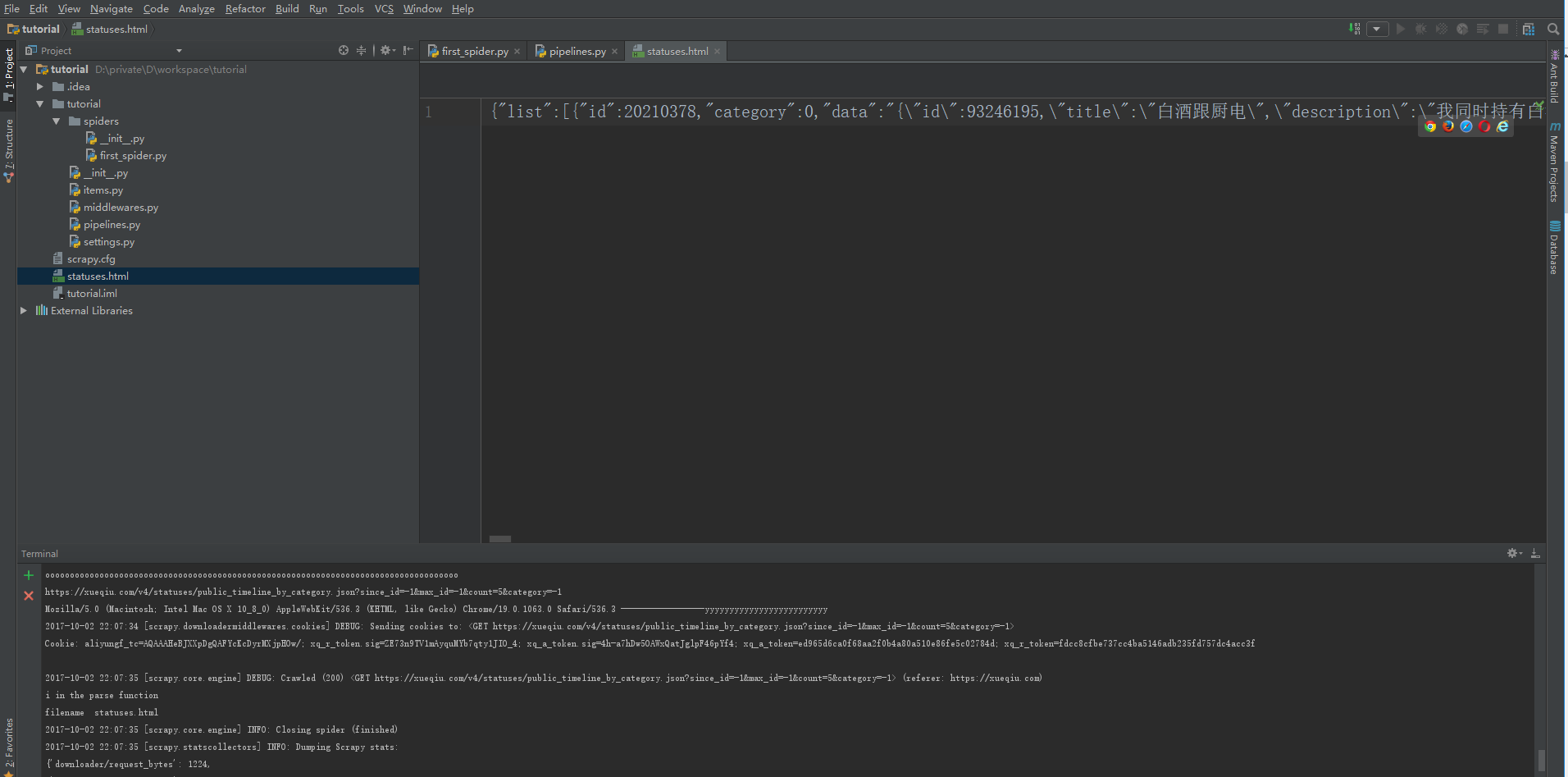
至此,我们拿到了雪球的头条。
最近,薛之谦的大战很火啊,下一篇我们讲讲怎们实时把薛之谦,李雨桐的微博实时发送到微信,让我们第一时间,掌握八卦的细节。

